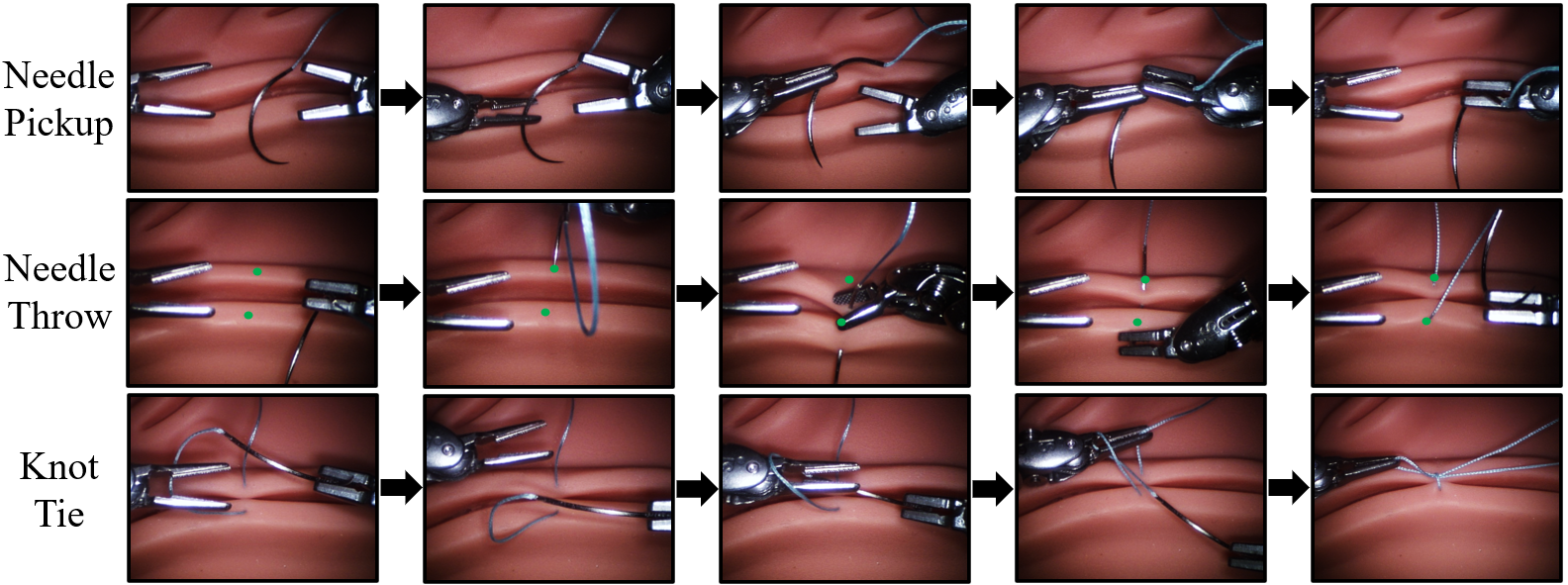
Robotic suturing is a prototypical long-horizon dexterous manipulation task, requiring coordinated needle grasping, precise tissue penetration, and secure knot tying.
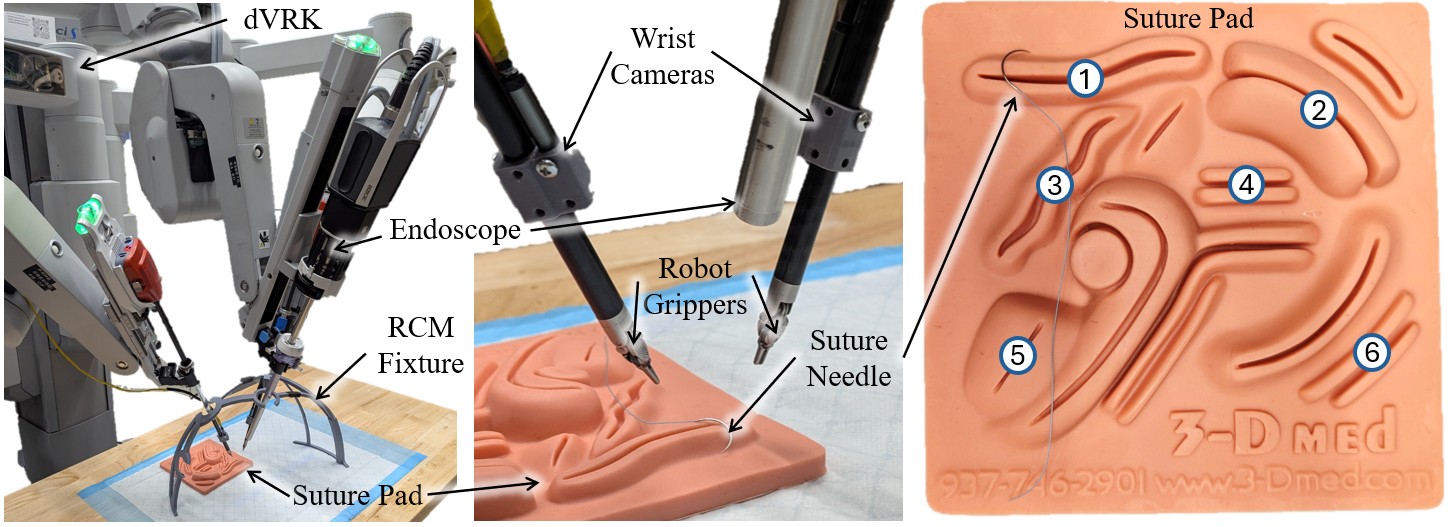
Despite numerous efforts toward end-to-end autonomy, a fully autonomous suturing pipeline has yet to be demonstrated on physical hardware. We introduce SutureBot: an autonomous suturing benchmark on the da Vinci Research Kit (dVRK), spanning needle pickup, tissue insertion, and knot tying. To ensure repeatability, we release a high-fidelity dataset comprising 1,890 suturing demonstrations.
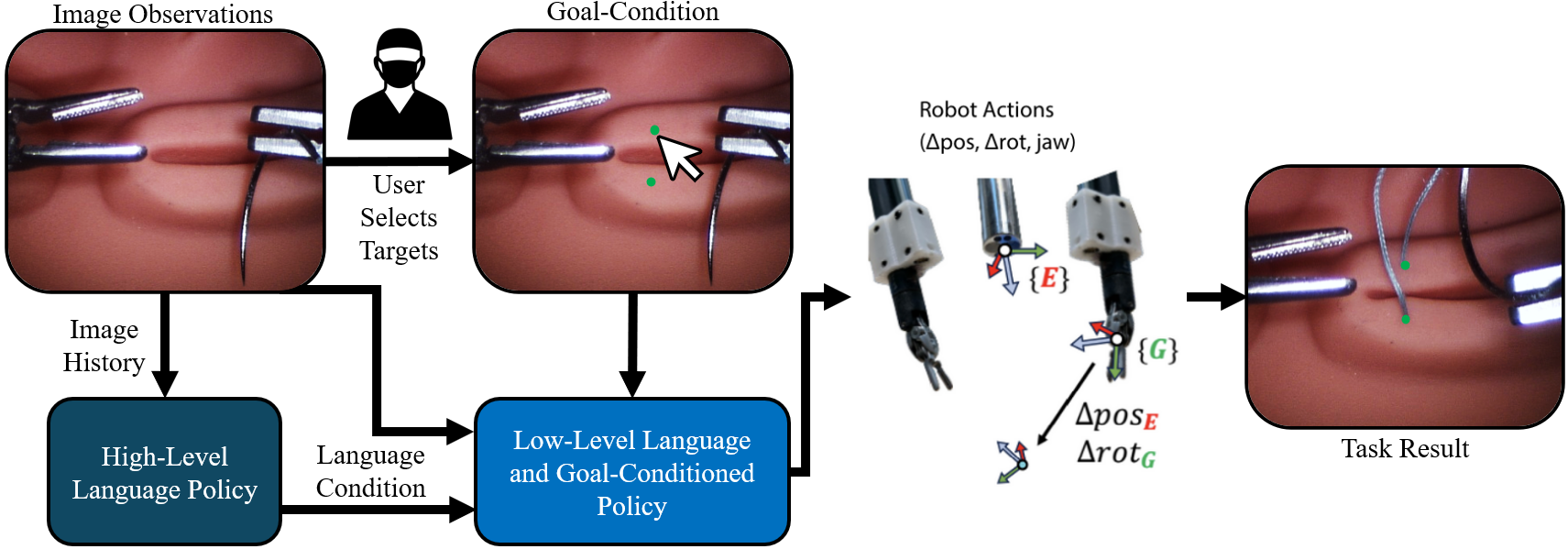
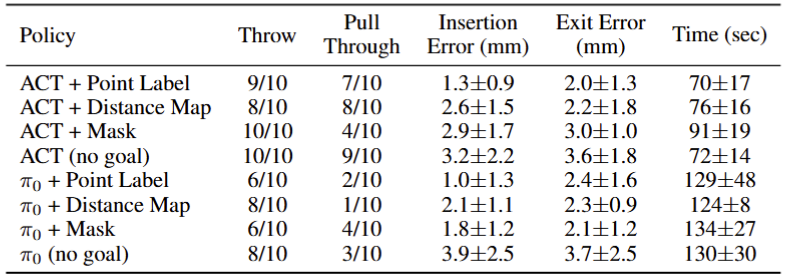
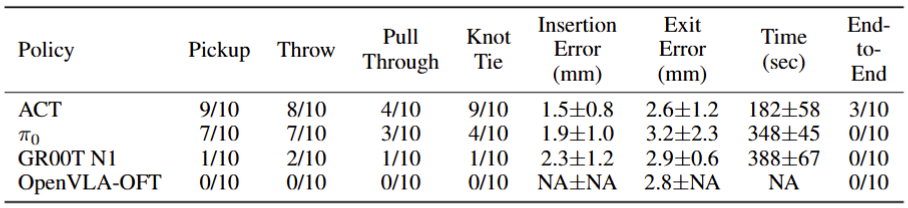
Furthermore, we propose a goal-conditioned framework that explicitly optimizes insertion-point precision, improving targeting accuracy by 59%-74% over a task-only baseline. To establish this task as a benchmark for dexterous imitation learning, we evaluate state-of-the-art vision-language-action (VLA) models, including π0, GR00T N1, OpenVLA-OFT, and multitask ACT, each augmented with a high-level task-prediction policy. Autonomous suturing is a key milestone toward achieving robotic autonomy in surgery. These contributions support reproducible evaluation and development of precision-focused, long-horizon dexterous manipulation policies necessary for end-to-end suturing.